Azure Function to vectorise PDFs and store in Qdrant container app with OpenAI and Python

Some of the links in this article are affiliate links. This means if you click on the link and purchase or subscribe, I will receive a commission. All opinions and recommendations remain objective. You can also read the affiliates disclosure for more information.
Introduction
In this one we'll be going through part of an LLM / Azure OpenAI project I worked on recently. This involved:
- Triggering an Azure Function app when a new PDF is dropped into an Azure Blob Storage container.
- Vectorising the document in the Azure Function app.
- Dropping those vectors into a Qdrant database running in an Azure Container app.
- A Python FastAPI app which retrieved and queried those document vectors to answer user questions.
I will be outlining the process and code on how to vectorise documents in an Azure Function, but cannot give too much detail due to the organisation's data protection policy.
I have redacted some details in the images, but you should get a good feel for how to put together a solution like this if it's something you're interested in. It was quite a lightweight solution but still had many moving parts.
There are tools that make this process easier and do the heavier lifting which I'm learning about currently including Azure Prompt Flow and Azure AI Search for documents. However this process is more customisable and provides greater control.
Drop a PDF into blob storage
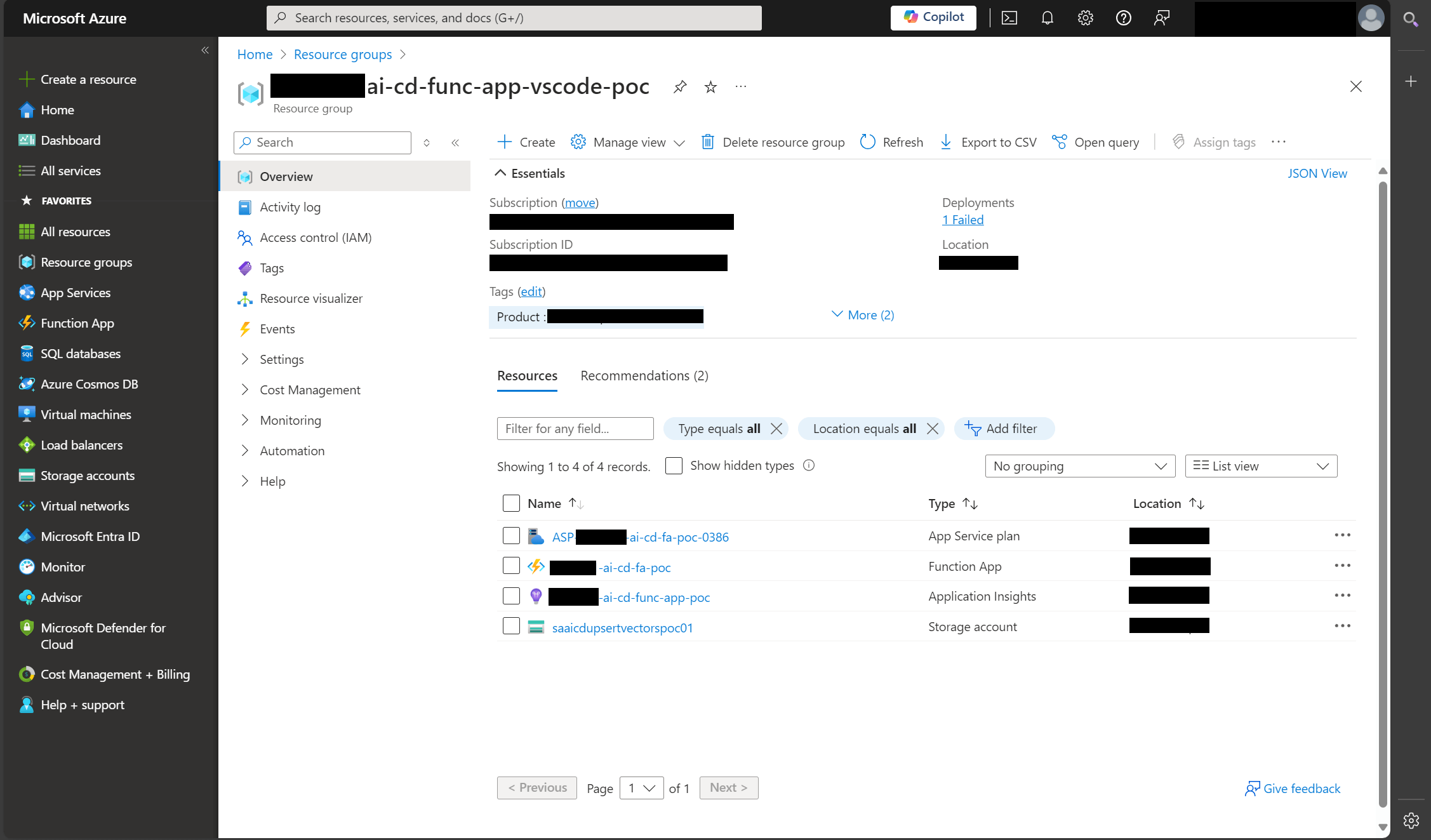
The first step was to set up a resource group in Azure, and create these components:
- Blob storage container
- Function app
- Qdrant container app
Once a new PDF is dropped into the storage account, the function app is automatically triggered and begins to run.
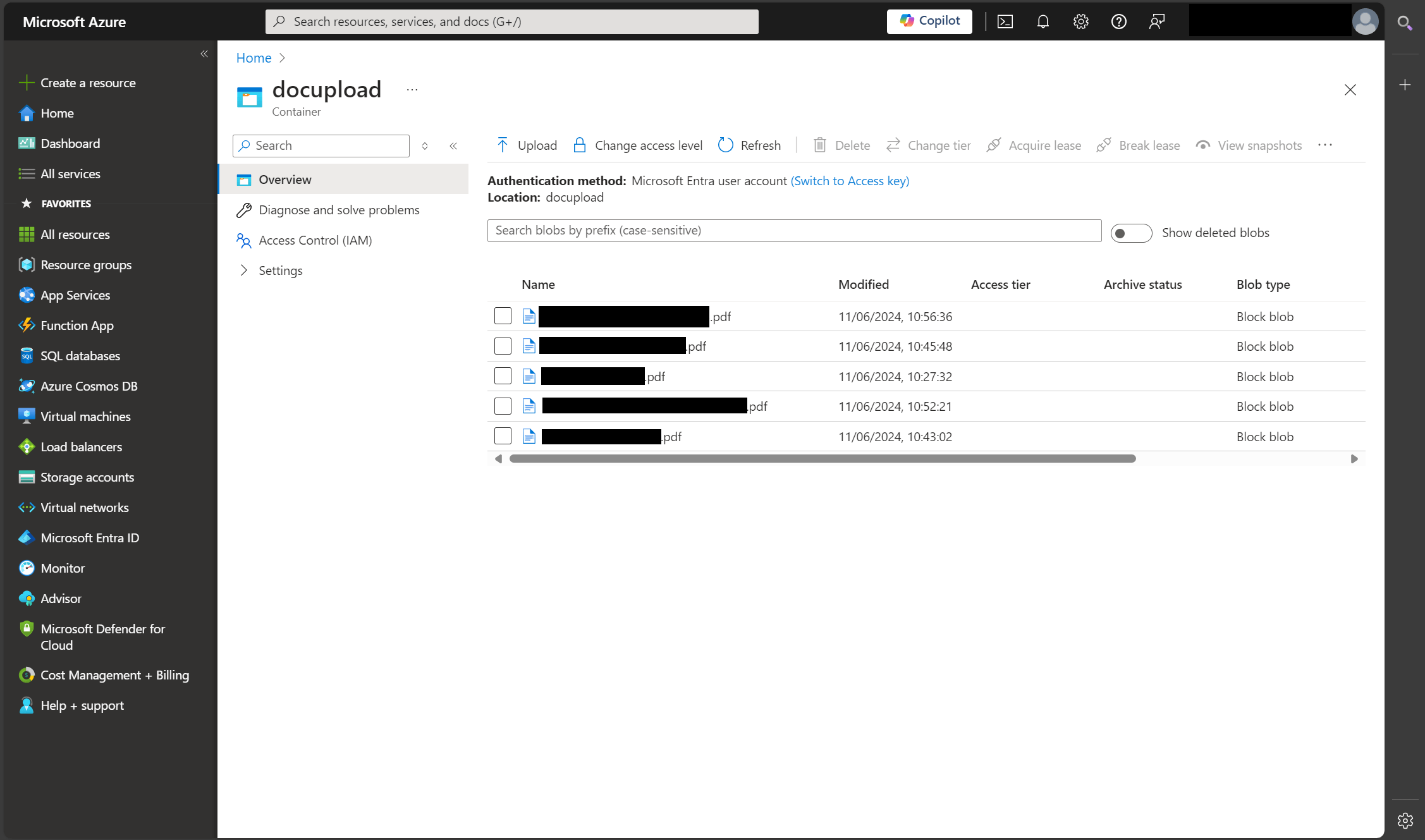
Function app automatically triggers
The function app is triggered now that a new PDF has been uploaded to the blob storage container. Here is the trigger configured in the function app.

Here is the Python code that drives the vectorisation process. The docstring at the top of the file outlines the steps the function app takes. It triggers, reads the PDF, vectorises, and stores the vectors.
"""
An Azure function app which:
- is triggered when a new PDF file is added to the blob container 'docupload'
- reads the PDF file and turns to vectors
- stores the vectors in Azure Qdrant
Components:
- Function app
- Blob store
- Qdrant container
Prerequisites:
- Install VS Code Azure extension
- Read getting started documentation at https://shorturl.at/59jYg
"""
import azure.functions as func
import logging
import fitz
import openai
import qdrant_client.models as models
import tiktoken
from langchain.text_splitter import RecursiveCharacterTextSplitter
from qdrant_client import QdrantClient
from qdrant_client.http.models import *
from qdrant_client.fastembed_common import *
app = func.FunctionApp()
@app.blob_trigger(arg_name="myblob", path="docupload",
connection="saaicdupsertvectorspoc01_STORAGE")
def aicdfaupsertvectorspoc(myblob: func.InputStream):
# 1. Read document
blob_name: str = myblob.name
logging.info(f"Python blob trigger function processed blob"
f"Name: {myblob.name}"
f"Blob Size: {myblob.length} bytes")
''
try:
document = fitz.open(stream=myblob.read(), filetype="pdf")
logging.info(f'PDF read successfully: {document}')
except:
print("The PDF could not be read.")
# 2. Vectorise document and upload to Qdrant
def tiktoken_len(text: str) -> int:
tokenizer = tiktoken.get_encoding("p50k_base")
tokens = tokenizer.encode(text, disallowed_special=())
return len(tokens)
def data_upload(qdrant_index_name: str, document) -> None:
settings = {
"url": "https://ca-qdrant-poc.azurecontainerapps.io", # The URL to your container app
"host": "ca-qdrant-poc.azurecontainerapps.io",
"port": "6333",
"openai_api_key": "", # Enter your OpenAI API key
"openai_embedding_model": "text-embedding-ada-002"
}
whole_text = []
for page in document:
text = page.get_text()
text = text.replace("\n", " ")
text = text.replace("\\xc2\\xa3", "£")
text = text.replace("\\xe2\\x80\\x93", "-")
whole_text.append(text)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=tiktoken_len,
separators=["\n\n", "\n", " ", ""],
)
chunks = []
for record in whole_text:
text_temp = text_splitter.split_text(record)
chunks.extend([{"text": text_temp[i]} for i in range(len(text_temp))])
try:
client = QdrantClient(url=settings["url"],
port=None)
collection_names = []
collections = client.get_collections()
for i in range(len(collections.collections)):
collection_names.append(collections.collections[i].name)
if qdrant_index_name in collection_names:
client.get_collection(collection_name=qdrant_index_name)
else:
client.create_collection(
collection_name=qdrant_index_name,
vectors_config=models.VectorParams(
distance=models.Distance.COSINE, size=1536
),
)
except Exception as e:
logging.error("Unable to connect to QdrantClient")
logging.error(f"Error message: {str(e)}")
for id, observation in enumerate(chunks):
text = observation["text"]
try:
openai.api_key = settings["openai_api_key"]
res = openai.Embedding.create(
input=text, engine=settings["openai_embedding_model"]
)
except openai.AuthenticationError:
logging.error("Invalid API key")
except openai.APIConnectionError:
logging.error(
"Issue connecting to open ai service. Check network and configuration settings"
)
except openai.RateLimitError:
logging.error("You have exceeded your predefined rate limits")
client.upsert(
collection_name=qdrant_index_name,
points=[
models.PointStruct(
id=id,
payload={"text": text},
vector=res.data[0].embedding,
)
],
)
logging.info("Text uploaded")
logging.info("Embeddings upserted")
file_index = blob_name \
.strip() \
.lower() \
.replace(" ", "_") \
.replace("docupload/", "") \
.replace(".pdfblob", "") \
.replace(".pdf", "")
logging.info(f"File index: {file_index}")
data_upload(qdrant_index_name=file_index, document=document)
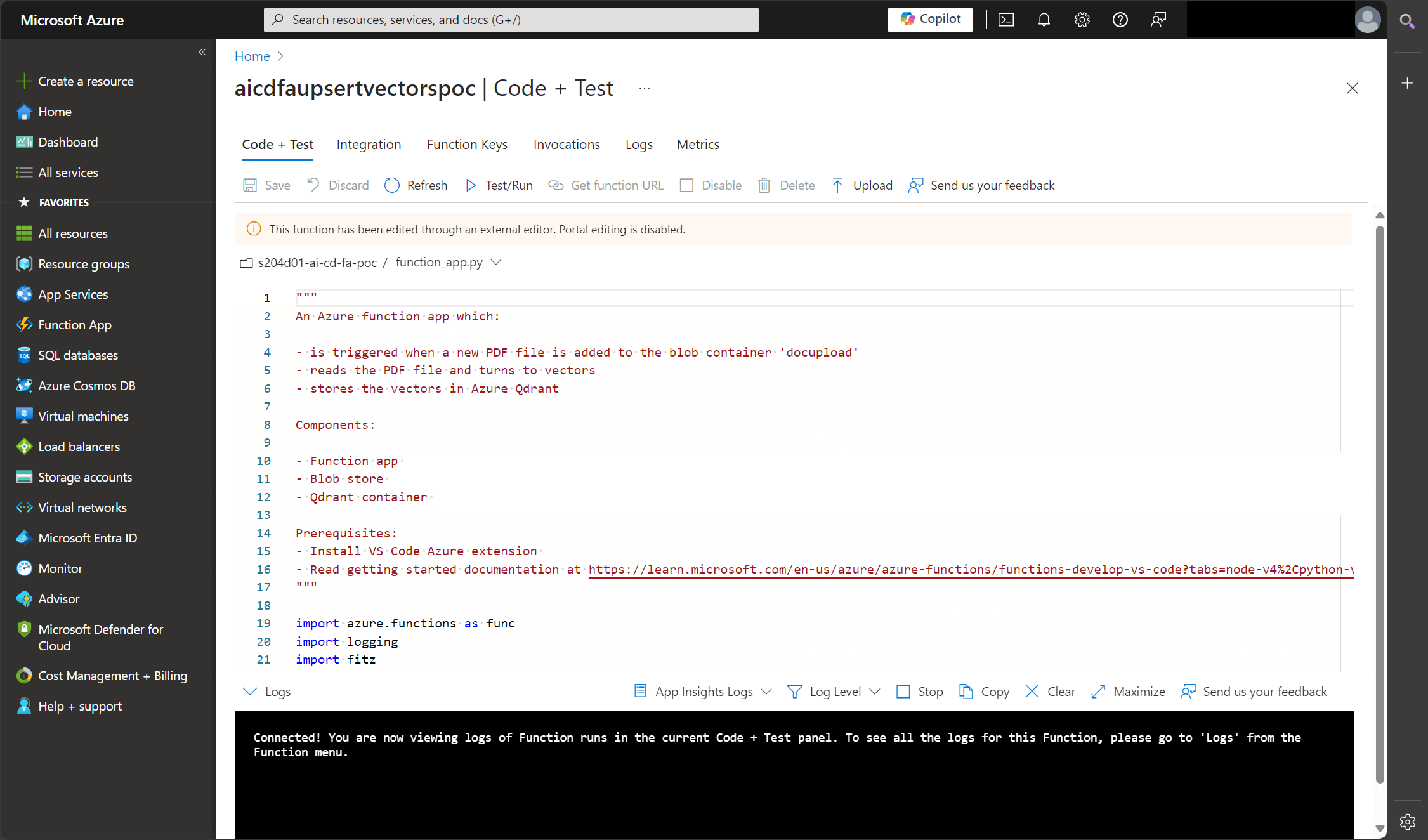

So above we can see the Azure function in the Azure portal and in VS Code, and the run logs - yes I found 65 ways to fail here but eventually found a way to succeed! The full logs end with "Embeddings upserted" so we know it completed successfully.

Now to check the Qdrant container app to confirm for sure that the vector embeddings are present there.
Vectors stored in Qdrant container app
The Qdrant container app was set up in Azure to hold the vector embeddings.
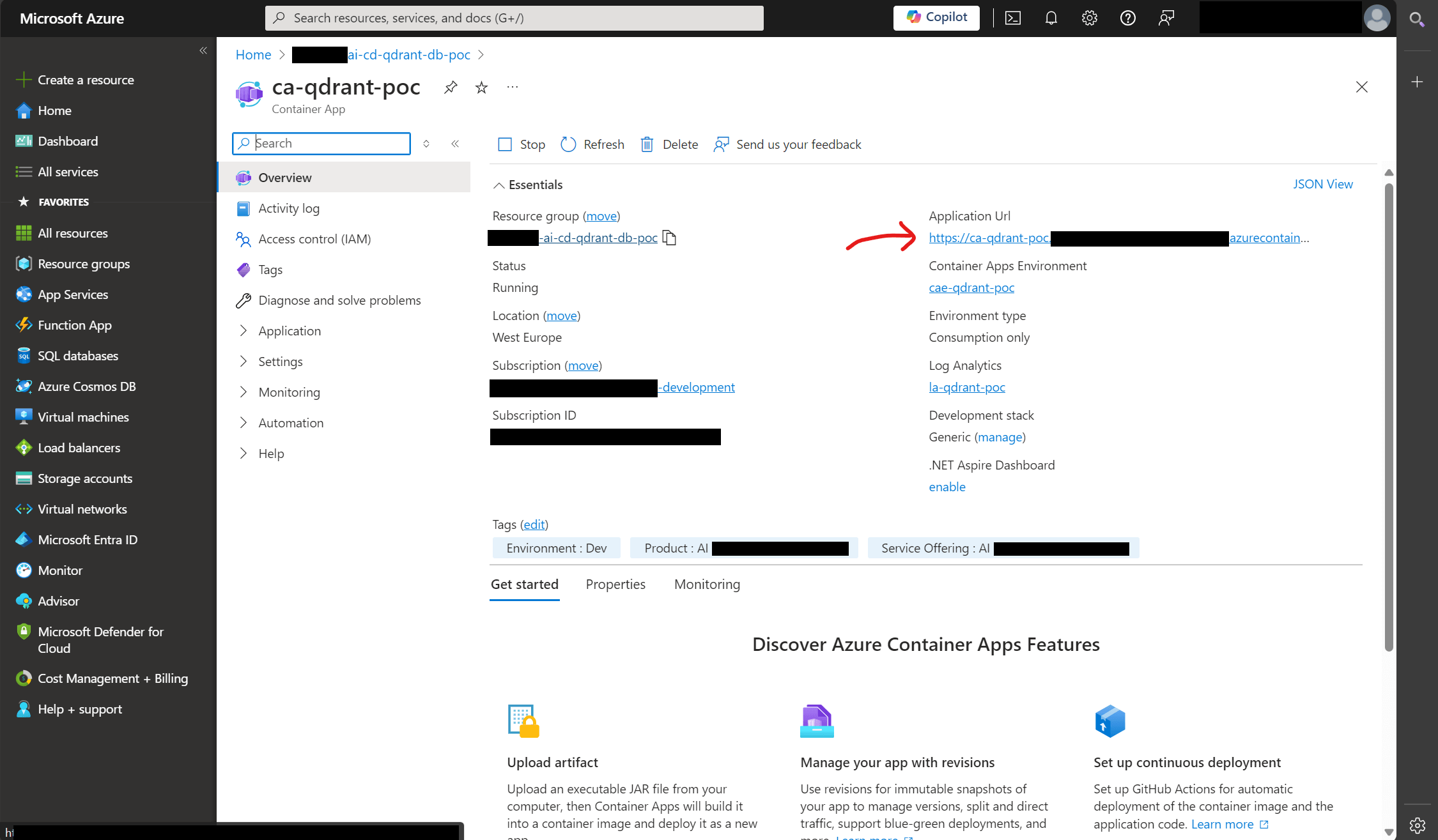
If we head to that URL given for the container app and add /dashboard/collections we will see all of the document vector collections present in Qdrant.
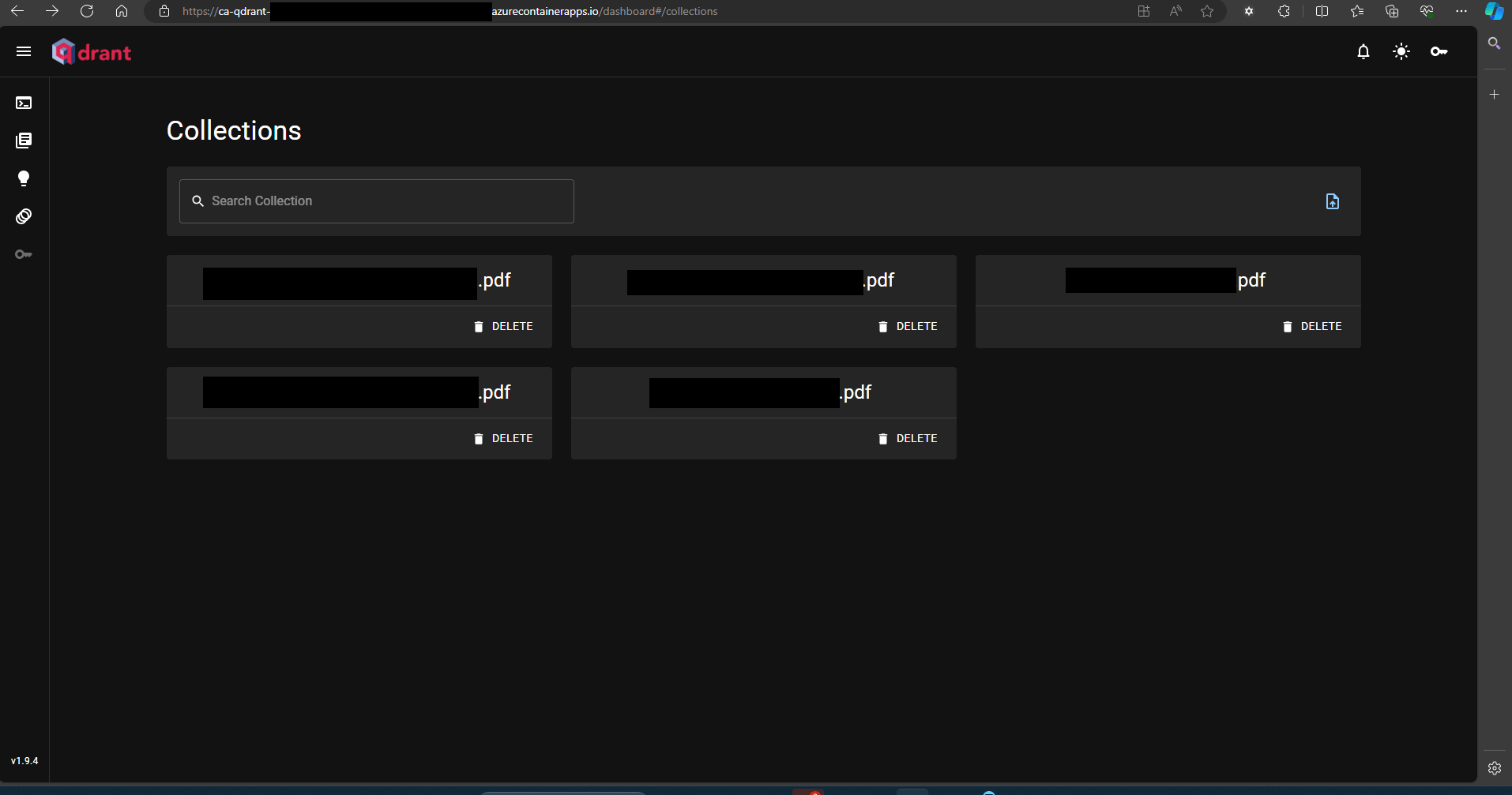
Selected a collection shows the vector embeddings that are stored in it. By vectorising and chunking the PDF content and storing it in a Qdrant vector database this can now work with the OpenAI LLM to answer questions based on the PDF documents.
Bonus: Saving snapshots for backups
I found during this process a useful feature for backup and disaster recovery planning. Once a PDF has been vectorised and upserted, you can save a snapshot of the vectors in the Qdrant dashboard.
If everything is wiped, you can just upload the snapshot to a collection and you're back up and running. This gives a secondary option to re-running the function app for all the documents.


How can I learn more about LLMs, Qdrant and OpenAI in Python?
First off, if you know nothing the freeCodeCamp course and video A Non-Technical Introduction to Generative AI is great.
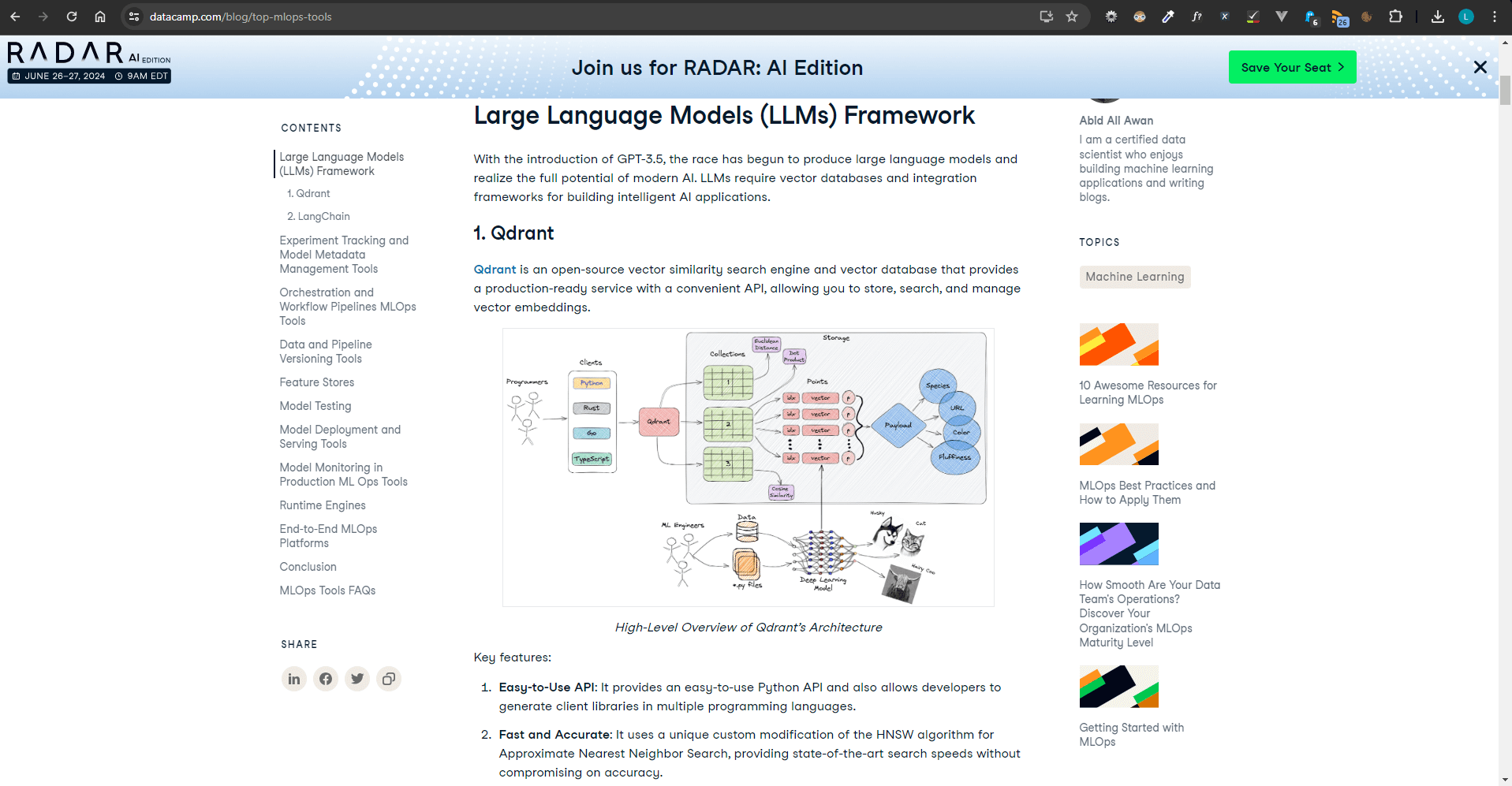
Secondly, this is a useful article from DataCamp on the 25 Top MLOps Tools You Need to Know in 2024 which includes Qdrant and LangChain.
Lastly, to learn more about using OpenAI with Python there is a DataCamp course Working with the OpenAI API or you can check out the openai-python GitHub repo.
Wrap up
That's everything for this one! There are lots of things to explore when it comes to LLMs and the new tools that are emerging. This was a pretty simple use case but required some discovery and learning to figure out how to do this.
I hope you enjoyed this article and it helps you out if you're planning on embarking on the same wild journey of vectorising documents in Azure from scratch! Thanks for reading. If you know even easier way to query and answer questions based on documents please share them in the comments section at the bottom of this page. I will likely write another article on the entire solution once it's fully completed. Keep an eye out for that.
Since you read this article all the way to the end you might also be interested in:



