Concepts of Artificial Intelligence with Python - a review of CS50 AI

Some of the links in this article are affiliate links. This means if you click on the link and purchase or subscribe, I will receive a commission. All opinions and recommendations remain objective. You can also read the affiliates disclosure for more information.
This article covers the concepts of Artificial Intelligence (AI) introduced in Harvard's CS50 Introduction to Artificial Intelligence with Python course, along with a review of the course itself, what I learned from it, and helpful advice if you're looking to start it yourself. Spoiler alert, when outlining the projects for each week I may include example code, you might want to skip over these parts if you're taking the course yourself.
So what is CS50 AI all about?
CS50's Introduction to Artificial Intelligence (AI) with Python explores the concepts and algorithms at the foundation of modern artificial intelligence, diving into the ideas that give rise to technologies like game-playing engines, handwriting recognition, and machine translation. Through hands-on projects, students gain exposure to the theory behind graph search algorithms, classification, optimization, reinforcement learning, and other topics in artificial intelligence and machine learning as they incorporate them into their own Python programs. By course’s end, students emerge with experience in libraries for machine learning as well as knowledge of artificial intelligence principles that enable them to design intelligent systems of their own.
The course contains seven lectures, twelve projects and seven quizzes. The lectures and projects cover key AI concepts such as search, knowledge, uncertainty, optimisation, machine learning, neural networks and natural language processing. The suggested completion time is seven weeks, at between ten to thirty hours per week. The only prerequisites for the course are either taking the CS50 Introduction to Computer Science course or prior programming experience in Python. The course is free and if you submit and receive a score of at least 70% on each of this course’s projects, you will be eligible for a free certificate like the one below. A nice recognition of the hard work put in to get it. 🤓 You can also choose to pay £145 (at the time of writing) to get a verified certificate from edX. This might be worthwhile if you are wanting to show to an employer or talk about in an interview.

If you've already achieved a verified certificate for CS50 Introduction to Computer Science (I completed this in 2018 and loved the course) then after completing this course in AI you in turn complete the Professional Certificate in Computer Science for Artificial Intelligence. Both of these courses combined make for a solid introduction to Computer Science. In covering programming, web development, probability, machine learning and artificial intelligence you have the foundation to enter a number of career paths including Software Engineer and Data Scientist roles. CS50 in collaboration with edX offers a few different 'pathways' as outlined below.
| Level | Course | Estimated Duration | Topics | Languages Covered | Certificate | Final Certificate (combined with CS50) |
|---|---|---|---|---|---|---|
| Core | CS50's Introduction to Computer Science | 12 weeks 6-18 hours per week | Abstraction, Algorithms, Data Structures, Encapsulation, Software Engineering, and Web Development | C, Python, SQL, and JavaScript plus CSS and HTML | $90 edX (What I paid, might have changed) | - |
| Specialist | CS50's Web Programming with Python and JavaScript | 12 weeks 6-9 hours per week | Git, Models, Migration, User Interfaces, Testing, CI/CD, Scalability, Security | HTML, CSS, Python, SQL, JavaScript | $199 edX (may have now changed) | Professional Certificate in Computer Science for Web Programming |
| Specialist | CS50's Mobile App Development with React Native | 13 weeks 6-9 hours per week | Components, Props, State, Views, Navigation, User Input, Performance, Shipping, Testing | JavaScript | $199 edX (may have now changed) | Professional Certificate in Computer Science for Mobile Apps |
| Specialist | CS50's Introduction to Game Development | 12 weeks 6-9 hours per week | 2D and 3D Graphics, Animation, Sound, Collision Detection, Unity, LOVE 2D | Lua, C# | $199 edX (may have now changed) | Professional Certificate in Computer Science for Game Development |
| Specialist | CS50's Introduction to Artificial Intelligence with Python | 7 weeks 10-30 hours per week | Graph Search Algorithms, Knowledge Representation, Logical Inference, Probability, Machine Learning | Python | $199 edX (may have now changed) | Professional Certificate in Computer Science for Artificial Intelligence |
AI is the ability of a machine to display human-like capabilities such as reasoning, learning, planning and creativity. AI has completely changed the world and has the potential to continually do so. I do think however, that it can be misunderstood. I see people using the term "artificial intelligence" without realising fully what it means - particular the difference between strong and weak AI. The uses of AI day to day are vast, including search engines, predictive search, image recognition, games, voice assistants, email spam detection, bank fraud detection, smart devices, movie and music recommendations, chatbots, finding map directions and more. Other applications that might soon be seen more often include autonomous drones, self-driving vehicles, robots and virtual workers.


I think the great thing about this course, is that it lifts the lid on what otherwise can be seen as a black box, to explore the concepts and algorithms that are key to implementing AI systems. It gives you the core knowledge required to build your own intelligent programs which "mimic the problem-solving and decision-making capabilities of the human mind" (IBM). Although not essential, I would recommend the book Artificial Intelligence: A Modern Approach as a companion to the course.
The following sections cover the core concepts covered in each lecture, and the projects completed with links to my submitted code in GitHub. If you are taking the course yourself, you should not view these solutions as it might be seen as breaking Academic Honesty.
Okay, let's dive into the concepts covered in the course!
Lecture 0: Search
Concepts:
- Agent: entity that perceives its environment and acts upon that environment.
- State: a configuration of the agent and its environment.
- Actions: choices that can be made in a state.
- Transition model: a description of what state results from performing any applicable action in any state.
- Path cost: numerical cost associated with a given path.
- Evaluation function: function that estimates the expected utility of the game from a given state.
Algorithms:
- DFS (depth first search): search algorithm that always expands the deepest node in the frontier.
- BFS (breath first search): search algorithm that always expands the shallowest node in the frontier.
- Greedy best-first search: search algorithm that expands the node that is closest to the goal, as estimated by an heuristic function h(n).
- A* search: search algorithm that expands node with lowest value of the "cost to reach node" g(n) plus the "estimated goal cost" h(n). In other words, g(n) is the number of steps you had to take to get to the node you're at and the h(n) is the 'Manhatten distance' heuristic estimate of how far a node is away from the goal. This can be expressed as f(n) = g(n) + h(n).
- Minimax: adversarial search algorithm.
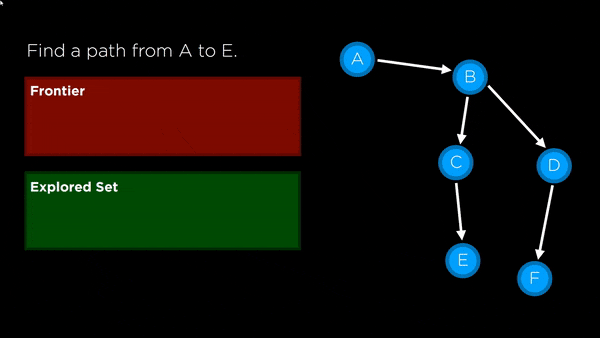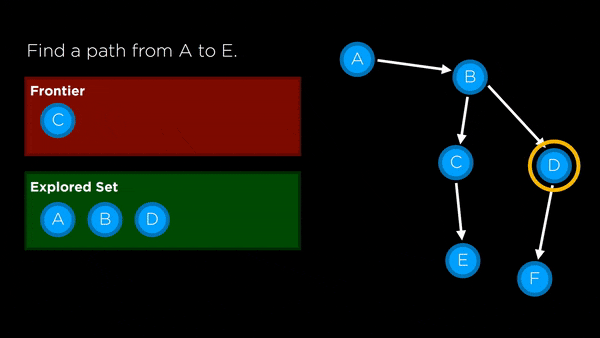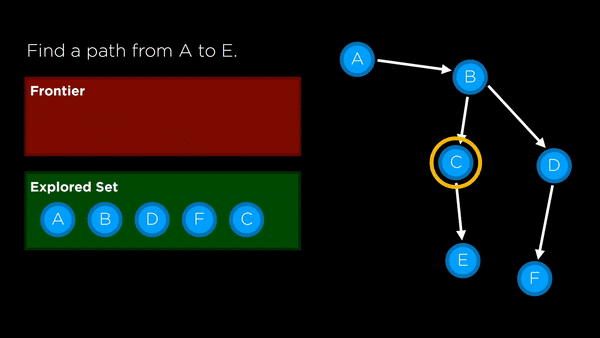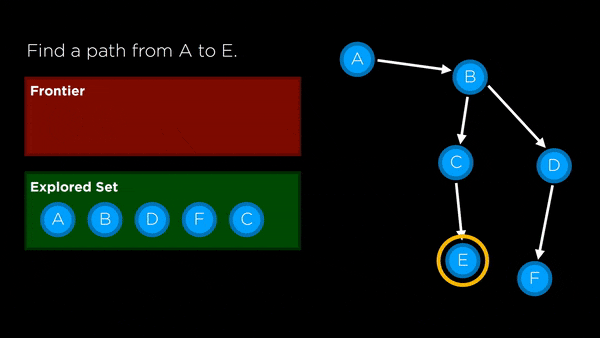

Data Structures
- Frontier: represents all the possible nodes to search next that haven’t yet been explored
- Stack: last-in first-out data type used for DFS
- Queue: first-in first-out data type used for BFS
- Node: keeps track of a state, a parent (node that generated this node), an action (action applied to parent to get to node) and a path cost (from initial state to node)
Projects
- Tic-Tac-Toe - Using Minimax, implement an AI to play Tic-Tac-Toe optimally. [Solution]
- Degrees - Write a program that determines how many “degrees of separation” apart two actors are. [Solution]
def shortest_path(source, target):
"""
Finds the shortest path between any two actors (source, target)
by choosing a sequence of movies that connects them.
Returns the shortest list of (movie_id, person_id) pairs
that connect the source to the target.
If no possible path, returns None.
"""
print(
f"Finding shortest path between {people[source]['name']} ({source}) and {people[target]['name']} ({target})...")
timer = time.time()
# Start with frontier and initial node
frontier = QueueFrontier()
initial_node = Node(state=source, parent=None, action=None)
frontier.add(initial_node)
# Start with empty explored set
explored = set()
number_of_states_explored = 0
while True:
# If frontier is empty no solution
if frontier.empty():
return None
# Remove a node from the frontier
node = frontier.remove()
number_of_states_explored += 1
# Add the node to the explored set
explored.add(node.state)
# Expand node, add resulting nodes to the frontier if the aren't already
# in the frontier or the explored set
for movie_id, person_id in neighbors_for_person(node.state):
if not frontier.contains_state(person_id) and person_id not in explored:
child = Node(state=person_id, parent=node, action=movie_id)
# If child node (neighbor) contains goal state, no need to add it to the frontier
# instead return the solution immediately.
if child.state == target:
path = []
node = child
while node.parent is not None:
path.append((node.action, node.state))
node = node.parent
path.reverse()
seconds_taken = time.time() - timer
print(f"Explored { number_of_states_explored } states in { seconds_taken } seconds")
return path
frontier.add(child)
There are two approaches to the order of this solution, one of them dramatically reduces time complexity.
Submitting the first project
I started CS50 AI a while back, but other commitments got in the way. So I was really happy to dive back in. I'd already done the tictactoe project so I submitted that first (I know it was the second project, but it interested me more so I did it first 😆). The first obstacle you might hit on week 0 is "I've finished my first project... How do I submit my work?!"
I had the same question. So let's take submitting tictactoe as an example. In the main CS50 AI site in the tictactoe project page, there is a section "Getting started" to pull the project code from. Once the project is completed, we have a section 'How to Submit' which contains a series of steps:
- Visit this link, log in with your GitHub account, and click Authorize cs50. Then, check the box indicating that you’d like to grant course staff access to your submissions, and click Join course.
- Install Git and, optionally, install submit50.
- If you’ve installed submit50, execute
submit50 ai50/projects/2020/x/tictactoe - Submit this form.
I had a folder structure broken down by lecture and project:
0. Search
| --- degrees
| --- tictactoe
|
1. Knowledge
| --- knights
| --- minesweeper
...
Seems straightforward but there were a few gotchas. So here is how I stumbled through it:
- cd into project directory
Search/tictactoe - I tried install submit50 on Windows using
pip3 install submit50. This is a no-no it does not work on Windows. So I launched Ubuntu (which has Python preinstalled) on a virtual machine using VirtualBox - To install the Python packages for the project (for tictactoe it was pygame) alongside submit50 I needed to install pip using
sudo apt install python3-pip - I could now install submit50 using
pip3 install submit50 - Once submit50 is installed I needed to reboot the Ubuntu virtual machine to ensure the terminal recognised it (I was getting
submit50: Command not found) - In the project directory I could now install all the packages using
pip3 install -r requirements.txt- you might want to create and install packages to a virtual environment per project folder if you wish - I was then able to run tictactoe for testing using
python3 runner.py
These steps got me very close to my first submission. There were two more obstacles... Since I was using VS Code within Ubuntu everytime I tried to submit GitHub would open in the browser, I'd sign in but submission would fail when I returned to VS Code. The solution is go to File > Preferences > Settings > Extensions > GitHub and untick Git Authentication 😄
So now when using submit50 ai50/projects/2020/x/tictactoe to submit, the prompt for my GitHub username and password would appear within VS Code itself, much better. The final hurdle was, if you have two factor authentication turned on with GitHub, you might get this message 😧

The link provided in the error message https://cs50.ly/github-2fa has all the steps for creating a personal access token. Once you have it, re-submit and use that token at the password prompt. Now using submit50 ai50/projects/2020/x/tictactoe again, the submission for tictactoe was successfully uploaded!
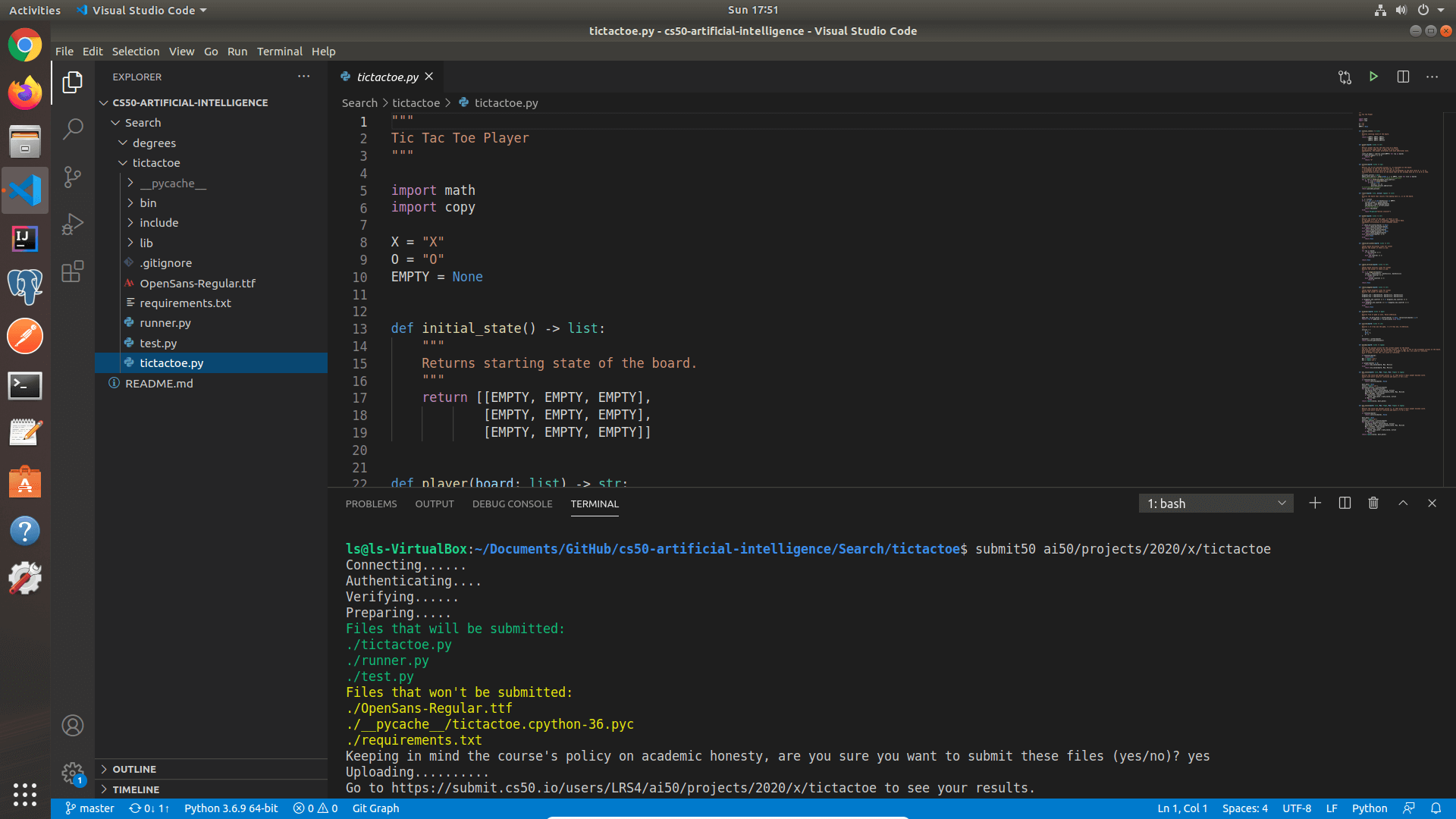
Hopefully this should serve as a good example of how to submit tictactoe, and you can now use the same method for submitting each of the other projects. You might find a much easier way to do this, I'm sure you could use Windows Subsystem for Linux instead, but this worked nicely for me even if there were a few headaches to overcome.
Lecture 1: Knowledge
Concepts
- Sentence: an assertion about the world in a knowledge representation language.
- Knowledge base: a set of sentences known by a knowledge-based agent.
- Entailment: a entails b if in every model in which sentence a is true, sentence b is also true.
- Inference: the process of deriving new sentences from old ones.
- Conjunctive normal form: logical sentence that is a conjunction of clauses.
- First order logic: Propositional logic.
- Second order logic: Proposition logic with universal and existential quantification.
- Truth table: table showing the outputs for all possible combinations of inputs to a logic gate or circuit.
Algorithms
- Model checking: enumerate all possible models and see if a proposition is true in every one of them.
- Conversion to CNF and Inference by resolution
Projects
- Knights - Write a program to solve logic puzzles [Solution]
- Minesweeper - Write an AI to play Minesweeper [Solution]
I think the Minesweeper project was one of my favourite! The general logic of the AI was adding sentences to it's knowledge base where a sentence consisted of a set of board cells,
and a count of the number of those cells which are mines, so something like Sentence({(0, 1), (1, 0), (1, 1)}, 3). This says out of cells {(0, 1), (1, 0), (1, 1)} exactly 3 of them are mines. We can then infer they must all be mines as the number of cells is equal to the count! On every move the following process was executed:
- Mark the cell as a move that has been made
- Mark the cell as safe
- Get the neighbours of the current cell
- Add a new sentence to the AI's knowledge base based on the cell's neighbours and count (of adjacent mines)
- Mark any additional cells as safe or as mines if it can be concluded based on the AI's knowledge base
- Add any new sentences to the AI's knowledge base if they can be inferred from existing knowledge
This meant that as sentences are added to the knowledge base the AI can make yet more inferences.

Given this board, we can see there is one mine next to the top row cells and two mines next to the bottom middle cell. The top row's sentence would be {A, B, C} = 1. the bottom middle's sentence would be {A, B, C, D, E} = 2. Now we have two sentences where the first sentence's set of cells are a subset of the second sentence's set of cells. We can now construct a new sentence by doing set2 - set1 = count2 - count 1 which is {D, E} = 1. If two of A, B, C, D, and E are mines, and only one of A, B, and C are mines, then it stands to reason that exactly one of D and E must be the other mine.
Here is a demo of the Minesweeper AI in action!
Lecture 2: Uncertainty
When the answer isn't certain, we can use probability based methods to assess the knowledge available, to then make decisions.
Concepts
- Unconditional probability: degree of belief in a proposition in the absence of any other evidence.
- Conditional probability: degree of belief in a proposition given some evidence that has already been revealed.
- Possible worlds: every possible outcome for a given series or combination of events
- Random variable: a variable in probability theory with a domain of possible values it can take on.
- Independence: the knowledge that one event occurs does not affect the probability of the other event.
- Bayes' Rule: P(a) P(b|a) = P(b) P(a|b)
- Bayesian network: data structure that represents the dependencies among random variables.
- Markov assumption: the assumption that the current state depends on only a finite fixed number of previous states.
- Markov chain: a sequence of random variables where the distribution of each variable follows the Markov
assumption.
- Hidden Markov Model: a Markov model for a system with hidden states that generate some observed event.
Algorithms
- Inference by enumeration
- Sampling
- Likelihood weighting
Projects
- Heredity - Write an AI to assess the likelihood that a person will have a particular genetic trait. [Solution]
- PageRank - Write an AI to rank web pages by importance. [Solution]
Having worked as a Data Scientist and Statistician, I like the following questions for starting to think about probability. Firstly, if you have two fair dice, what is the probablity of rolling a 12 (6 and 6)? The answer is 1 in 36 or a 2.778% chance because we can see out of all the 36 possible words (the possible combinations of dice throws) only one satisfies the requirement of rolling a 12.

I read in the book The Art of Statistics: Learning from Data about how in 2012, 97 Members of Parliament were asked 'If you spin a coin twice, what is the probablity of getting two heads?' 60 out of 97 of them couldn't give the correct answer. The answer is 1 in 4 or a 25% chance because we can see out of the 4 possible outcomes only one satisfies the requirement of flipping two heads.
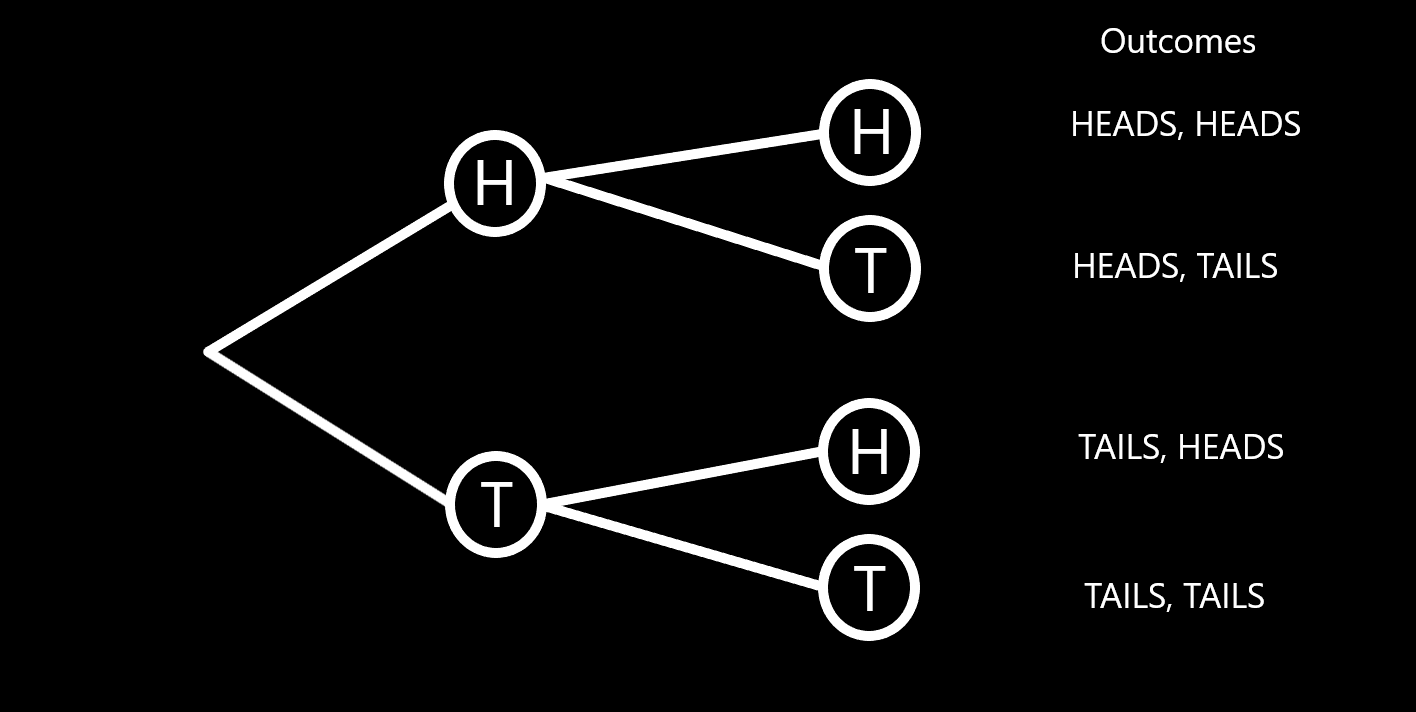
Another favourite of mine that seemingly breaks the laws of probablity is the Monty Hall Problem. There is a follow up explanation for this and an excellent comment on this video from Rundvelt showing the importance of looking at 'possible worlds':
I think that if you drew out all the possibilities that would demonstrate the fact better. For example.
Scenario 1: Car / Goat / Goat
Scenario 2: Goat / Car / Goat
Scenario 3: Goat / Goat / Car
Let's say you pick the door on the left and do not switch.
Scenario 1: Win
Scenario 2: Lose
Scenario 3: Lose
Let's say you pick the door on the left and switch doors.
Scenario 1: Lose
Scenario 2: Win
Scenario 3: Win.
Not Switching = 1 win out of 3.
Switching = 2 wins out of 3.
To learn more about statistics and probability, I recommend the book Practical Statistics for Data Scientists - I love using this as a reference book.
Lecture 3: Optimisation
Optimisation can be summarised as choosing the best option from a set of options.
Concepts
- Local search: search algorithm that maintain a single node and searches by moving to a neighbouring node, but is not concered about finding the path, just the optimal solution.
- State-space landscape: the different configuations of possible worlds and their cost value.
- Objective function: function to find the global maximum from the state space landscape.
- Cost function: function to find the global minimum from the state space landscape.
- Neighbouring state: a state that is close to the current state, but slightly different to compare objective or cost function value.
Algorithms
- Hill Climbing: start at a given state, then consider the neighbours of that state and pick the highest or lowest.
- steepest-ascent: choose the highest-valued neighbour.
- stochastic: choose randomly from higher-valued neighbours.
- first-choice: choose the first higher-valued neighbour.
- random-restart: conduct hill climbing multiple times.
- local beam search: chooses the k highest-valued neighbours.
- Simulated Annealing: early on, more likely to accept worse-valued neighbours than the current state.
- Linear Programming: a method to achieve the best outcome (such as maximum profit or lowest cost) in a mathematical model whose requirements are represented by linear relationships.
- Constraint Satisfaction problems: problems where the state has constraints or limiations.
- Node Consistency: when all the values in a variable's domain satisfy the variable's unary constraints.
- Arc Consistency: when all the values in a variable's domain satisfy the variable's binary constraints.
Backtracking Search: a search algorithm to solve a constraint satisfcation problem that incrementally builds candidates as the solution, but abandons a candidate ('backtracks') as soon as it finds the candidate cannot possibly be a valid solution.

Projects
- Crossword - Write an AI to generate crossword puzzles. [Solution]
Lecture 4: Learning
Machine learning models focus on finding and learning from patterns in existing data, then use those patterns to predict new outcomes with a high degree of accuracy. Although accuracy is important it's also essential to build explainable models / explainable AI (XAI) so subjects, stakeholders and businesses can understand them and have more confidence in them.
Concepts
- Supervised learning: given a data set of input-output pairs, learn a function to map inputs to outputs.
- Classification: supervised learning task of learning a function mapping an input point to a discrete category.
- Regression: supervised learning task of learning a function mapping and input point to a continuous value.
- Loss function: function that express how poorly our hypothesis performs (L1, L2).
- Overfitting: when a model fits too closely to a particular data set and therefore may fail to generalize to
- Regularization: penalizing hypotheses that are more complex to favor simpler, more general hypotheses.
- Holdout cross-validation: splitting data into a training set and a test set, such that learning happens on the
- k-fold cross-validation: splitting data into k sets, and experimenting k times, using each set as a test
- Reinforcement learning: given a set of rewards or punishments, learn what actions to take in the future.
- Unsupervised learning: given input data without any additional feedback, learn patterns.
- Clustering: organizing a set of objects into groups in such a way that similar objects tend to be in the same
group.
Algorithms
- k-nearest-neighbor classification: given an input, chooses the most common class out of the k nearest data
points to that input.
- Support Vector Machines (SVM): algorithm which creates a line or a hyperplane which separates the data into classes.
- Markov decision process: model for decision-making, representing states, actions and their rewards.
- Q-learning: method for learning a function Q(s, a), estimate of the value of performing action a in state s.
- Greedy decision-making
- epsilon-greedy
- k-means clustering: clustering data based on repeatedly assigning points to clusters and updating those
clusters' centers.
Basic template for building a machine learning classifier model
import pandas as pd
import numpy as np
from sklearn.svm import SVC
from sklearn.linear_model
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
model = KNeighborsClassifier()
data = pd.read_csv("filepath goes here.csv")
target = data['ColumnName'].values
features = data['ColumnNameA', 'ColumnNameB', 'ColumnNameC']
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.3
)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
correct = (y_test == predictions).sum()
incorrect = (y_testing != predictions).sum()
total = len(predictions)
print(f"Results for model {type(model).__name__}")
print(f"Correct: {correct}")
print(f"Incorrect: {incorrect}")
print(f"Accuracy: {100 * correct / total:.2f}%")
Packages
- pandas: fast, powerful, flexible and easy to use open source data analysis and manipulation tool,built on top of the Python programming language.
- scikit-learn: Machine learning and predictive analysis package built on NumPy, SciPy, and matplotlib. [Lecture]
Resources
Projects
- Shopping - Write an AI to predict whether online shopping customers will complete a purchase. [Solution]
- Nim - Write an AI that teaches itself to play Nim through reinforcement learning. [Solution]
Lecture 5: Neural Networks
An artificial nerual network is a mathematical model for learning inspired by biological neural networks.
Concepts
- Multilayer neural network: artificial neural network with an input layer, an output layer, and at least one hidden layer.
- Deep neural network: neural network with multiple hidden layer.
- Dropout: temporarily removing units - selected at random - from a neural network to prevent over-reliance on certain units.
- Computer vision: computational methods for analysing and understanding digital images.
- Image convolution: applying a filter that adds each pixel value of an image to its neighbours, weighted according to a kernel matrix.
- Pooling: reducing the size of an input by sampling from regions in the input.
- Convolutional neural network: neural networks that use convolution, usually for analyzing images.
- Recurrent neural network: neural network that generates output that feeds back into its own inputs.
Algorithms
- Gradient descent: algorithm for minimizing loss when training neural network.
- Backpropagation: algorithm for training neural networks with hidden layers.
Packages
- tensorflow: An open source software library for high performance numerical computation. It comes with strong support for machine learning and deep learning and the flexible numerical computation core is used across many other scientific domains. See also The Sequential model with Tensorflow Keras.
- scikit-learn: A machine learning and predictive analysis package built on NumPy, SciPy, and matplotlib.
- opencv-python: A library of Python bindings designed to solve computer vision problems. See docs.
Projects
- Traffic - Write an AI to identify which traffic sign appears in a photograph. [Solution]
After downloading the distribution code, install the Python packages from the requirements file, I ran python3 traffic.py gtsrb as a test and received an Illegal instruction (core dumped) error message. I was running this on an Ubuntu Linux VM using VirtualBox. The fix for this was to re-install an earlier version of the tensorflow package:
pip3 uninstall tensorflow
pip3 install tensorflow==1.5
After this I ran python3 traffic.py gtsrb again and arrived at the line 62 not implemented error in the load_data function, as expected, File "traffic.py", line 62, in load_data raise NotImplementedError. Hope this helps you out if you find yourself getting the same error message!
Here is a demo of the Convolutional Neural Network model used for the Traffic project in action!
Lecture 6: Language
Natural Language Processing or NLP aims to understand human language, both written and spoken to extract information.
Concepts
- n-gram: a contiguous sequence of n items inside of a text.
- Tokenization: the task of splitting a sequence of characters into pieces (tokens).
- Text Categorization
- Bag-of-words model: represent text as an unordered collection of words.
- Information retrieval: the task of finding relevant documents in response to a user query.
- Topic modeling: models for discovering the topics for a set of documents.
- Term frequency: number of times a term appears in a document.
- Function words: words that have little meaning on their own, but are used to grammatically connect other words.
- Content words: words that carry meaning independently.
- Inverse document frequency: measure of how common or rare a word is across documents. Formula is log(total_documents / number_of_documents_containing(word))
- Information extraction: the task of extracting knowledge from documents.
- WordNet: a lexical database of semantic relations between words.
- Word representation: looking for a way to represent the meaning of a word for further processing.
- one-hot: representation of meaning as a vector with a single 1, and with other values as 0.
- distribution: representation of meaning distributed across multiple values.
Algorithms
- Markov model applied to language: generating the next word based on the previous words and a probability.
- Naive Bayes: based on the Bayes' Rule to calculate probability of a text being in a certain category, given it contains specific words. Assuming every word is independent of each other.
- Additive smoothing: adding a value a to each value in our distribution to smooth the data.
- Laplace smoothing: adding 1 to each value in our distribution (pretending we've seen each value one more time than we actually have).
- tf-idf: ranking of what words are important in a document by multiplying term frequency (TF) by inverse document frequency (IDF).
- Automated template generation: giving AI some terms and let it look into a corpus for patterns where those terms show up together. Then it can use those templates to extract new knowledge from the corpus.
- word2vec: model for generating word vectors.
- skip-gram architecture: neural network architecture for predicting context words given a target word.
Packages
Projects
- Parser - Write an AI to parse sentences and extract noun phrases. [Solution]
- Questions - Write an AI to answer questions. [Solution]
Reflections on the course
Overall I found the course challenging yet extremely informative on the concepts and implementations of AI. It had the right balance between abstract concepts and concrete solutions in Python. I'm now much more aware of and always on the look out for applying these AI concepts to problems, or whether a problem can be framed as one of them. I think just knowing how to solve certain kinds of problems is half the battle, the other half is shaping the problem into a workable solution. To do that you need solid robust data, and a clear vision for the 'world' in which the AI agent will operate.
We have already seen widespread use of AI and this can only increase in the coming decades. I think having an understanding of the fundamentals and building your own small AI solutions is essential, especially for Software Engineers and Data Scientists. The main aim in building intelligent systems for me, is to enable the autonomous agents that operate within their 'world' to carry out tasks and make decisions at or above the accuracy a human domain expert could, but faster and more reliably. To achieve that, it may involve a combination of machine learning, statistics, software engineering, system architecture and data engineering skills, plus business domain knowledge. As shown in the below image, there is generally an overlap between roles and skills, but in my opinion all of of these skills have a benefit to any digital or data role.

The concepts and skills learnt in this course certainly help to get you started on your journey to engineering intelligent, autonomous systems and your own AI programs that can help make other people's lives better. The certification is optional, however I opted to purchase it and have talked about it and the skills gained from it within interviews. I think it demonstrates a commitment to continuing professional development, an attitude of continuous learning and an accolade you can be proud of upon finishing the course.
As always, if you enjoyed this article be sure to check out other articles on the site including Developing your data science and analytical coding skills - a review of DataCamp 😄