How to scrape AutoTrader with Python and Selenium to search for multiple makes and models

Searching for used cars can be time consuming and sometimes there isn't a good way to easily compare potential cars. AutoTrader is a great place to perform this search and comparison but as far as I can see, it does not allow to search for multiple makes and models in one search.
Who wants to keep going back and forth between previously saved searches, right? Wouldn't it be so much easier if you could compare all of them in one list or spreadsheet? We'll explore the Python code that does just that using both Selenium and regular expressions (RegEx), along with a video demo of how to use it.
Installing required Python packages
Of course, you'll need the latest stable version of Python installed on your operating system and added to path before progressing. I'm also using Visual Studio Code as the code editor, this isn't essential but it's a great free lightweight IDE worth checking out.
Following that, the autotrader scraper will rely on a few Python packages so using pip, install the following for specific version I used at the time of writing:
python -m pip install numpy pandas==2.2.3 bs4==0.0.1 selenium==4.15.1 xlsxwriter==1.4.3
Or the latest versions with:
python -m pip install numpy pandas bs4 selenium xlsxwriter
The main libraries we are using here are:
- Selenium to control ChromeDriver, navigate to URLs etc.
- Beautiful Soup to parse and search the HTML elements
- Pandas for data manipulation and calculations
- XlsxWriter to create the Excel output including conditional formatting
All other libraries such as os re, time and datetime come as standard with the Python standard library.
Downloading ChromeDriver
Selenium effectively 'controls' or 'drives' a web browser in an automated way. In order to do that, we need ChromeDriver, and we need the version that matches your current version of Chrome.
My version of Chrome was 'Version 119.0.6045.106 (Official Build) (64-bit)'. You can find your current version of Chrome by hitting the three dots in the top right of the browser > Help > About Google Chrome.
You will see your current version and an option to update if it isn't the latest version.

So based on that, I required the latest stable version of ChromeDriver for my machine which was '119.0.6045.105 win64'.

If you already have Version 119.0.6045.106 you can just head to this repository where I have stored the code alongside the version of 'chromedriver.exe' I used ready for cloning / download.
Explaining the AutoTrader scraper
To simplify the code block below and to understand the process, here is a 3 step summary of what's going on.
- We set our
criteriaandcarssearch parameters. - Then we
scrape_autotrader:- For each car find how many pages of results there are in
number_of_pages - For each page scrape all the
articles - For each article use RegEx to find all the car
details - Store all car details in a list
dataand return this
- For each car find how many pages of results there are in
- We take that, and
output_data_to_excel- Ensuring the data is parsed to numeric format
- Calculating mileage per annum
- Sorting on distance
- Conditional format the numeric columns red, amber, green for easier analysis
So once you've set your criteria and cars, ensure you're in the correct directory, then you can run the scraper using:
python autotrader-scraper.py
The code below then executes and begins the automated scraping in ChromeDriver.
# type: ignore
"""
Enables the automation of searching for multiple makes/models on Autotrader UK using Selenium and Regex.
Set your criteria and cars makes/models.
Data is then output to an Excel file in the same directory.
Running Chrome Version 119.0.6045.106 and using Stable Win64 ChromeDriver from:
https://googlechromelabs.github.io/chrome-for-testing/
https://edgedl.me.gvt1.com/edgedl/chrome/chrome-for-testing/119.0.6045.105/win64/chromedriver-win64.zip
"""
import os
import re
import time
import datetime
import pandas as pd
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
criteria = {
"postcode": "LS1 2AD",
"radius": "20",
"year_from": "2010",
"year_to": "2014",
"price_from": "3000",
"price_to": "6500",
}
cars = [
{
"make": "Toyota",
"model": "Yaris"
},
{
"make": "Honda",
"model": "Jazz"
},
{
"make": "Suzuki",
"model": "Swift"
},
{
"make": "Mazda",
"model": "Mazda2"
}
]
def scrape_autotrader(cars, criteria):
chrome_options = Options()
chrome_options.add_argument("_tt_enable_cookie=1")
driver = webdriver.Chrome()
data = []
for car in cars:
# Example URL:
# https://www.autotrader.co.uk/car-search?advertising-location=at_cars&include-delivery-option
# =on&make=Honda&model=Jazz&postcode=LS12AD&radius=10&sort=relevance&year-from=2011&year-to=2015
url = "https://www.autotrader.co.uk/car-search?" + \
"advertising-location=at_cars&" + \
"include-delivery-option=on&" + \
f"make={car['make']}&" + \
f"model={car['model']}&" + \
f"postcode={criteria['postcode']}&" + \
f"radius={criteria['radius']}&" + \
"sort=relevance&" + \
f"year-from={criteria['year_from']}&" + \
f"year-to={criteria['year_to']}&" + \
f"price-from={criteria['price_from']}&" + \
f"price-to={criteria['price_to']}"
driver.get(url)
print(f"Searching for {car['make']} {car['model']}...")
time.sleep(5)
source = driver.page_source
content = BeautifulSoup(source, "html.parser")
try:
pagination_next_element = content.find("a", attrs={"data-testid": "pagination-next"})
aria_label = pagination_next_element.get("aria-label")
number_of_pages = int(re.search(r'of (\d+)', aria_label).group(1))
except AttributeError:
print("No results found or couldn't determine number of pages.")
continue
except Exception as e:
print(f"An error occurred while determining number of pages: {e}")
continue
print(f"There are {number_of_pages} pages in total.")
for i in range(int(number_of_pages)):
driver.get(url + f"&page={str(i + 1)}")
time.sleep(5)
page_source = driver.page_source
content = BeautifulSoup(page_source, "html.parser")
articles = content.findAll("section", attrs={"data-testid": "trader-seller-listing"})
print(f"Scraping page {str(i + 1)}...")
for article in articles:
details = {
"name": car['make'] + " " + car['model'],
"price": re.search("[£]\d+(\,\d{3})?", article.text).group(0),
"year": None,
"mileage": None,
"transmission": None,
"fuel": None,
"engine": None,
"owners": None,
"location": None,
"distance": None,
"link": article.find("a", {"href": re.compile(r'/car-details/')}).get("href")
}
try:
seller_info = article.find("p", attrs={"data-testid": "search-listing-seller"}).text
location = seller_info.split("Dealer location")[1]
details["location"] = location.split("(")[0]
details["distance"] = location.split("(")[1].replace(" mile)", "").replace(" miles)", "")
except:
print("Seller information not found.")
specs_list = article.find("ul", attrs={"data-testid": "search-listing-specs"})
for spec in specs_list:
if "reg" in spec.text:
details["year"] = spec.text
if "miles" in spec.text:
details["mileage"] = spec.text
if spec.text in ["Manual", "Automatic"]:
details["transmission"] = spec.text
if "." in spec.text and "L" in spec.text:
details["engine"] = spec.text
if spec.text in ["Petrol", "Diesel"]:
details["fuel"] = spec.text
if "owner" in spec.text:
details["owners"] = spec.text[0]
data.append(details)
print(f"Page {str(i + 1)} scraped. ({len(articles)} articles)")
time.sleep(5)
print("\n\n")
print(f"{len(data)} cars total found.")
return data
def output_data_to_excel(data, criteria):
df = pd.DataFrame(data)
df["price"] = df["price"].str.replace("£", "").str.replace(",", "")
df["price"] = pd.to_numeric(df["price"], errors="coerce").astype("Int64")
df["year"] = df["year"].str.replace(r"\s(\(\d\d reg\))", "", regex=True)
df["year"] = pd.to_numeric(df["year"], errors="coerce").astype("Int64")
df["mileage"] = df["mileage"].str.replace(",", "").str.replace(" miles", "")
df["mileage"] = pd.to_numeric(df["mileage"], errors="coerce").astype("Int64")
now = datetime.datetime.now()
df["miles_pa"] = df["mileage"] / (now.year - df["year"])
df["miles_pa"].fillna(0, inplace=True)
df["miles_pa"] = df["miles_pa"].astype(int)
df["owners"] = df["owners"].fillna("-1")
df["owners"] = df["owners"].astype(int)
df["distance"] = df["distance"].fillna("-1")
df["distance"] = df["distance"].astype(int)
df["link"] = "https://www.autotrader.co.uk" + df["link"]
df = df[[
"name",
"link",
"price",
"year",
"mileage",
"miles_pa",
"owners",
"distance",
"location",
"engine",
"transmission",
"fuel",
]]
df = df[df["price"] < int(criteria["price_to"])]
df = df.sort_values(by="distance", ascending=True)
writer = pd.ExcelWriter("cars.xlsx", engine="xlsxwriter")
df.to_excel(writer, sheet_name="Cars", index=False)
workbook = writer.book
worksheet = writer.sheets["Cars"]
worksheet.conditional_format("C2:C1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
worksheet.conditional_format("D2:D1000", {
'type': '3_color_scale',
'min_color': '#f96a6c',
'mid_color': '#ffdc81',
'max_color': '#63be7b'
})
worksheet.conditional_format("E2:E1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
worksheet.conditional_format("F2:F1000", {
'type': '3_color_scale',
'min_color': '#63be7b',
'mid_color': '#ffdc81',
'max_color': '#f96a6c'
})
writer.close() # Previously writer.save()
print("Output saved to current directory as 'cars.xlsx'.")
if __name__ == "__main__":
data = scrape_autotrader(cars, criteria)
output_data_to_excel(data, criteria)
os.system("start EXCEL.EXE cars.xlsx")
If you don't want an Excel file with all the conditional formatting, after the transformations in output_data_to_excel remove everything at and below writer then just output to a CSV instead using:
df.to_csv("cars.csv")
I hope you find this code highly modifiable so you can adapt and extend it however you like.
I was keen to calculate the mileage per annum to assess wear and tear, but you might want to include other calculations to explore other aspects and take it even further!
There is also a way to avoid having to download the correct version of Chrome to match ChromeDriver. You can install webdriver-manager with:
pip install webdriver-manager
Then update the code to automatically download and provide the path to Selenium webdriver for ChromeDriver using webdriver-manager instead.
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
...
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
...
Taking the scraper for a test drive
Let's see the scraper in action, in this end-to-end demo. By performing this process weekly we can get the most up to date listing for a given area. In this demo, I have chosen a random postcode in Leeds.
The formatting after scraping makes it really easy to see the trade offs in terms of price, year, mileage, miles per annum and previous owners. It also nicely allows for further filtering to narrow down your parameters.
I closed the accept cookies pop up manually just so the steps taken in ChromeDriver were easily visible, but this isn't essential, you can just let it run.
Why did the previous scraper stop working?
For those of you who tried the old scraper from a previous article you'll know it stopped working after the AutoTrader UK website changed sometime after September 2023. All of the classes used for scraping changed and were obfuscated.
However, as we've seen in the current scraper, some attributes still allow element identification such as the data-testid attribute.
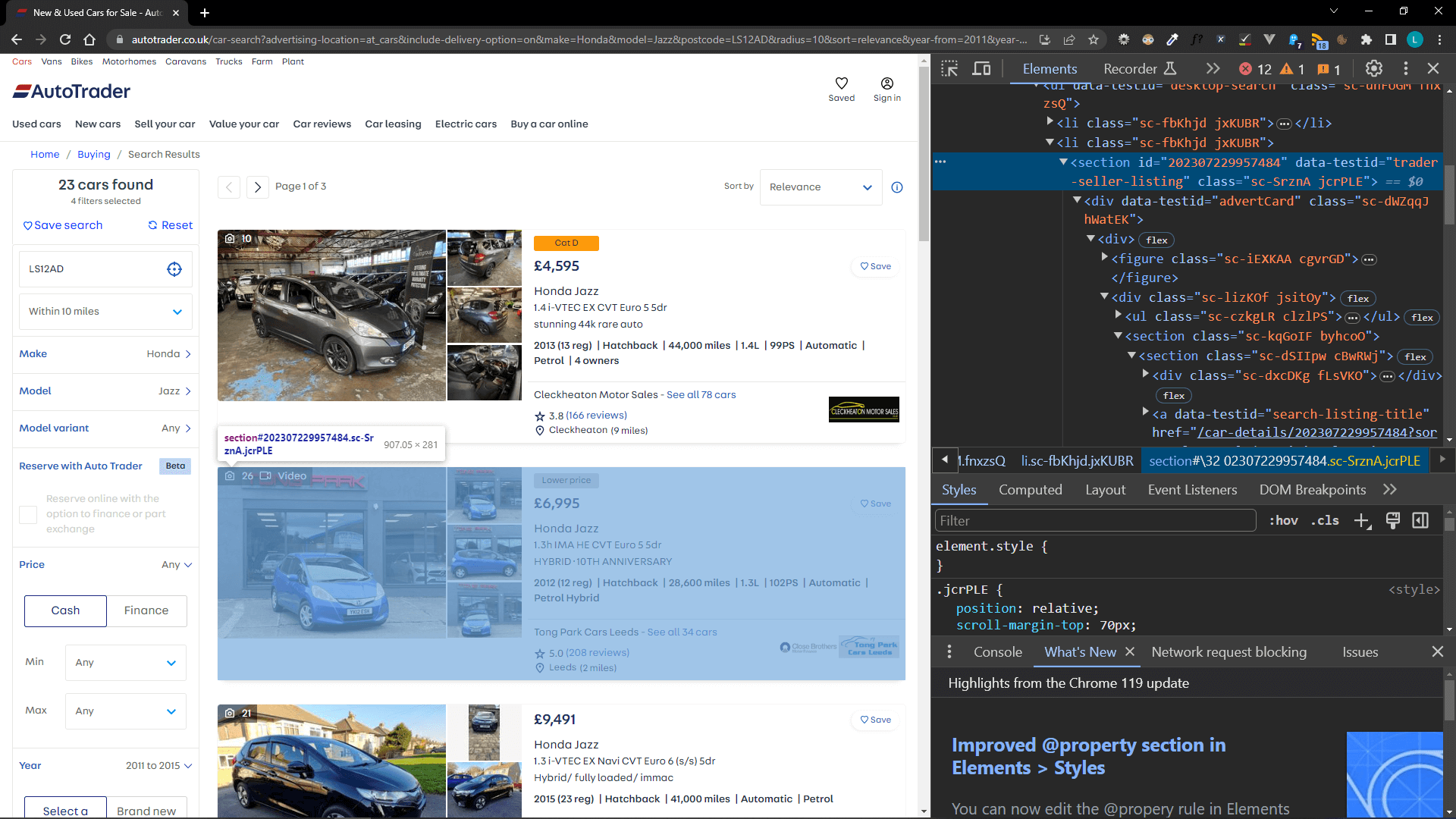
The current scraper is simpler, should be more robust and less reliant on third party code other than stable libraries.
However I have no doubt at some point it will stop working after another site change. Nevertheless, this scraper is easier to change, relying only on attribute identification followed by using regular expressions to find the required information. So by changing:
- How we are identifying elements with Beautiful Soup and
- How we are parsing the information out of those elements with RegEx
We can successfully update the code to adapt to changing needs. Selenium is a big help with this also, as it ensures that all scraping occurs after the page has loaded within Chrome. This means that anything that is dynamically added to the page using JavaScript after the page load should be captured.
Happy car hunting again!
The only thing left for you to do is set your criteria, add the makes and models you want, and off you go! Happy car hunting.
I hope the scraper helps you compare cars easier and find the one you're looking for as much as it helped me 👍
If you have any thoughts on this article, please leave a comment below or reach out by email at the bottom of this page. Certainly want to hear how this is being used, if it's helping others and how you've adapted it to your needs 😄
If you enjoyed this article be sure to check out: