How to learn Python for data analysis

This article will provide you with a clear, no-nonsense, step-by-step guide to learning Python for data analysis for beginners and intermediates. The goal of this article is to show you the areas you need to know and others you can dive deeper into, from the basics to the advanced stuff. Knowing the lay of the land is half the battle and this guide will show you what you need to know vs what you can delay until needed.
We'll explore the key practical skills and knowledge like Python's benefits for data analysis, installing Python for data analysis and it's basics. We'll discover the best Python packages for data science, data visualisation, and data manipulation workflows, along with advanced practical skills like API and SQL integration, web scraping, machine learning, natural language processing, large language models, and cloud computing. We'll start from basics to advanced, so you can progress through at your own pace.
Writing this article took me back in time to the beginning of my learning journey. I've been working in a Data Scientist role in a large organisation since 2019 and before that had other roles in analysis and digital. Although my university degree contained statistics, the course that really taught me hands-on practical skills was the Microsoft Professional Certificate in Data Science (no longer available) and the Data Analysis courses from DataCamp. Let's begin.
Why Python for data analysis?
In the analytical commmunity, Python and R seem to dominate as the go-to languages. Python has great packages for data science and ML and R does too with the Tidyverse. Both help to create reproducible analytical pipelines or RAP, which provides a robust framework for recreating findings way better than any Excel spreadsheet ever could.
Python is a beginner-friendly, versatile, and open-source programming language widely used for data analysis, with robust libraries and scalability for projects of any size. Its strong community support, industry-wide adoption, seamless integration with tools like SQL and Excel, and applicability to fields like machine learning and AI make it an essential tool for working with data.
Installing Python or Anaconda
For those getting started with Python for data analysis, installation is the first step to run any Python code on your machine. There are two ways to install Python either the base version or Anaconda, a platform designed specifically for data science and machine learning.
Option 1: Installing Python
- Download Python: Visit the official Python website and download the latest version for your operating system.
- Install Python:
- Run the installer and follow the on-screen instructions.
- Ensure you tick the box to add Python to your system’s PATH during installation.
- Verify Installation:
- Open your terminal or command prompt and type
python --versionto confirm Python is installed.
- Open your terminal or command prompt and type
Option 2: Using Anaconda
Anaconda is a free, open-source distribution of Python tailored for data science. It comes preloaded with popular libraries like NumPy, Pandas, Matplotlib, and Jupyter Notebook.
- Download Anaconda:
- Visit the Anaconda website and download the latest version for your operating system.
- Install Anaconda:
- Run the installer and follow the instructions for your system.
- On Windows, ensure you choose the option to add Anaconda to your PATH (if prompted).
- Verify installation:
- Open a terminal and type
conda --versionto confirm the installation.
- Open a terminal and type
Which to choose?
Choose base Python if you prefer a lightweight setup and plan to install libraries manually or work on projects outside of data analysis. You can also use a virtual environment with base Python to install specific packages per project. We discuss this in the libraries section later.
Choose Anaconda if you’re focused on data science, as it provides a ready-to-use environment with most libraries pre-installed and easy access to Jupyter Notebook.
If using base Python you can install the essential libraries using pip in a new command prompt or terminal:
pip install numpy pandas matplotlib seaborn scikit-learn nltk spacy openai requests bs4
Choosing an IDE for Python
An Integrated Development Environment (IDE) is a tool for writing, testing, and debugging your Python code efficiently. I really like VS Code as a simple code editor with powerful add-ons or extensions but your main options include:
- VS Code - lightweight IDE with extensions, suited for both simple and complex Python workflows
- Jupyter Notebook - interactive, cell-based environment ideal for exploratory data analysis and visualisation
- Spyder - data science-focused IDE similar to RStudio with features like variable exploration and inline plotting, perfect for Anaconda users
- PyCharm - A professional-grade IDE with advanced debugging and refactoring tools, designed for large-scale Python projects
An alternative is to use cloud-based IDEs
Although I believe installing Python and an IDE locally is preferable for flexibility, you can also use a cloud-based IDE like Kaggle Notebooks or Google Colab. These are convienient, beginner-friendly and remove the need for local installations. These platforms mainly provide hosted Jupyter Notebook services, pre-installed libraries, and support real-time collaboration, making them good for group projects or learning on the go.
Python core knowledge
To use Python effectively for data analysis, you should be comfortable with a few basics. Start by learning how to import packages, which allow you to leverage pre-built functionalities (e.g., import numpy as np for numerical computations). Variables are used to store data, which can be of various types like integers, strings, and floats. Loops (for, while) enable repetitive tasks, and functions let you organise reusable code. These fundamentals provide the foundation for writing efficient and structured Python scripts.
# Import packages
import numpy as np
import pandas as pd
import math
# Variables and Data Types
name = "Data Analysis" # String
number = 42 # Integer
pi = 3.14159 # Float
# Loop
for i in range(1, 4):
print(f"Iteration {i}: Learning Python Basics")
# Function
def square(num):
"""Returns the square of a number."""
return num ** 2
result = square(5) # Call the function
print(f"The square of 5 is {result}")
Good resources for this stage are reading references like The Python Standard Library of Python's built-in functions, alongside W3Schools Python tutorials.
It's also very important to understand Python data structures like lists, sets, dictionaries, and tuples for beginners in data science. You will rely on these to parse data, hold it in memory and pass it into the libraries we'll look at later.
# Example: Using lists and dictionaries to store and Analyse student grades
students = [
{"name": "Alice", "grades": [85, 90, 88]},
{"name": "Bob", "grades": [72, 78, 80]},
{"name": "Charlie", "grades": [90, 92, 94]},
]
# Calculate and display average grades for each student
for student in students:
avg_grade = sum(student["grades"]) / len(student["grades"])
print(f"{student['name']} - Average Grade: {avg_grade:.2f}")
Python data analysis essential skills
Before we dive into the specific libraries in the next section, let's look at the essential skills needed to perform data analysis with Python:
- Basic Python programming - understand variables, data types, loops, and functions, see previous section
- Version control - understand why it's important to use version control with Git
- Virtual environments - understand why it's important to use either venv or pipenv to install packages per project
- Data cleaning - handling missing values and correct inconsistencies in datasets
- Data manipulation - use tools to transform, filter, and aggregate data
- Exploratory Data Analysis (EDA) - summarise datasets and identify patterns
- Data visualisation - create graphs and charts to present data insights
- File handling - read and write data in formats like CSV, Excel, and JSON
- Time-series analysis - Analyse and summarise date and time-based data
- Statistical analysis - Perform calculations like mean, median, correlation
- Automation - Write scripts to automate repetitive analysis tasks
- Library proficiency - Familiarity with essential Python libraries such as Pandas and NumPy
Good resources for this stage are Python for Data Analysis or Python Data Science Handbook alongside the pandas and numpy documentation. The Pandas getting started is very useful, so is the W3Schools Pandas tutorial.
To learn more about essential skills for a Data Analyst or Data Scientist I found these fairly clear descriptions at National Careers Service, Analysis Function and DDaT Capability Framework alongside my article Preparing for a statistical data science interview.
Python libraries for data analysis
In this section we will explore the top libraries for data analysis in Python. These are vital to learn more about and in each of these I have a quick example and links to the documentation for further study. If you learn these libraries inside out, you'll be a Python data analysis pro.
NumPy for numerical computation
Create and manipulate arrays, perform matrix operations, and optimise performance with NumPy.
import numpy as np
arr = np.array([1, 2, 3])
print(arr.mean())
Pandas for data manipulation
Read and process structured data (CSV, Excel, SQL) with Pandas. Think of this as the 'Excel equivalent' for data manipulation. Everything you could do in Excel, you can do in Pandas. Pandas is one of the most popular Python libraries for data science and is essential for tasks like data manipulation and cleaning. This will become your number one go-to library.
import pandas as pd
data = pd.read_csv('data.csv')
print(data.describe())
Matplotlib and Seaborn for data visualisation
Create high-quality visualisations with Matplotlib and Seaborn.
import matplotlib.pyplot as plt
import seaborn as sns
sns.histplot(data['column_name'])
plt.show()
To see great examples check out the Seaborn gallery.
Scikit-learn for machine learning
Perform predictive modelling, build classification, regression, and clustering models with scikit-learn.
from sklearn.linear_model import LinearRegression
model = LinearRegression().fit(X_train, y_train)
NLTK or spaCy for natural language processing
Perform text preprocessing and named entity recognition with NLTK or spaCy:
import nltk
from nltk.tokenize import word_tokenize
text = "Learn Python for data analysis!"
print(word_tokenize(text))
BeautifulSoup for web scraping
Scrape and parse web data using BeautifulSoup. It would be useful to know the structure of web pages by learning some basic HTML for this, especially the main HTML tags alongside id, class and xpath selectors to target HTML elements.
from bs4 import BeautifulSoup
import requests
response = requests.get("https://example.com")
soup = BeautifulSoup(response.content, "html.parser")
print(soup.title.text)
OpenAI for large language models (LLMs)
Use LLMs like GPT-4o for text and conversation generation but also analysing and summarising data with the OpenAI package.
import openai
import pandas as pd
openai.api_key = "your-api-key"
df = pd.DataFrame({
"Name": ["Alice", "Bob"],
"Age": [25, 30],
"Salary": [50000, 60000]
})
response = openai.Completion.create(
engine="text-davinci-003",
prompt=f"Analyse this data:\n{df.to_string(index=False)}",
max_tokens=100
)
print(response.choices[0].text.strip())
venv for virtual environments
Isolate your Python projects and manage dependencies effectively with venv. Last but certainly not least, since it may be the first thing you do on your project but I didn't want to confuse this section by putting this first. Understand why it's important to use virtual environments. In a nutshell, it means others (and servers in the cloud) use the exact same package versions as you so the code and dependencies work.
In a command prompt window or terminal:
# Create a virtual environment
python3 -m venv myenv
# Activate the virtual environment
# On Windows
myenv\Scripts\activate
# On macOS/Linux
source myenv/bin/activate
# Install dependencies in the virtual environment
pip install pandas numpy
Good resources for this stage are actually getting some data like in an Excel file, reading that into pandas and having a go at analysis! This repo awesome-public-datasets contains many dataset collections organised by topic. Other good choices include Find open data and ONS. Later in this article we look at a practical data analysis workflow with the Titanic dataset.
If you're feeling daring try some web scraping to get a table of data from a web page! The main thing is to get hands-on and learn by doing data analysis. If you need more inspiration in this process, check out Doing Data Science.
Querying APIs and SQL databases
Besides Excel and CSV files, the main data sources to interact with are APIs and SQL databases so it's very useful to understand how to get data from these.
Querying data from APIs
Fetch data from APIs using the requests library:
import requests
import pandas as pd
response = requests.get("https://api.example.com/data")
data = response.json()
df = pd.DataFrame(data)
print(df.head())
Querying data from SQL databases
Integrate SQL with Python for database queries:
For smaller projects using SQLite use SQLite3:
import sqlite3
conn = sqlite3.connect('example.db')
data = pd.read_sql_query("SELECT * FROM table_name", conn)
For larger projects using a SQL Server database use pyodbc:
import pyodbc
import pandas as pd
# Connect to the SQL Server
conn = pyodbc.connect(
"DRIVER={SQL Server};SERVER=your_server_name;DATABASE=your_database_name;UID=your_username;PWD=your_password"
)
# Query the database
query = "SELECT TOP 10 * FROM your_table_name;"
df = pd.read_sql(query, conn)
# Perform data analysis
print(df.describe())
# Close the connection
conn.close()
For larger projects using a Postgres database use psycopg2:
import psycopg2
import pandas as pd
# Connect to the PostgreSQL database
conn = psycopg2.connect(
dbname="your_database_name",
user="your_username",
password="your_password",
host="your_server_name",
port="your_port_number" # Default is 5432
)
# Query the database
query = "SELECT * FROM your_table_name LIMIT 10;"
df = pd.read_sql(query, conn)
# Perform data analysis
print(df.describe())
# Close the connection
conn.close()
Practical example of data analysis workflow
Below is a Python script that showcases a basic but realistic data analysis workflow with core data operations. This script demonstrates a practical example, analysing the well-known Titanic dataset to uncover insights about survival rates and passenger trends. This is a simple structured dataset which is easy to work with for beginners.
import pandas as pd
import matplotlib.pyplot as plt
# Step 1: Import and load data
url = "https://raw.githubusercontent.com/shedloadofcode/data-files/refs/heads/main/titanic.csv"
df = pd.read_csv(url)
print("First five rows of the dataset:")
print(df.head())
# Step 2: Explore the data
print("\nDataset Info:")
print(df.info())
print("\nSummary Statistics:")
print(df.describe())
# Step 3: Clean the data
print("\nMissing values before cleaning:")
print(df.isnull().sum())
# Drop rows with missing Embarked values
df = df.dropna(subset=['Embarked'])
# Fill missing Age values with the median
df['Age'] = df['Age'].fillna(df['Age'].median())
# Drop irrelevant columns
df = df.drop(columns=['Cabin', 'Name', 'Ticket'])
print("\nMissing values after cleaning:")
print(df.isnull().sum())
# Step 4: Transform and engineer the data by converting or adding columns
df['FamilySize'] = df['SibSp'] + df['Parch'] + 1
df['Sex'] = df['Sex'].map({'male': 0, 'female': 1})
df['AgeGroup'] = pd.cut(df['Age'], bins=[0, 12, 18, 35, 60, 80], labels=['Child', 'Teen', 'Young Adult', 'Adult', 'Senior'])
print("\nTransformed Dataset:")
print(df.head())
# Step 5: Analyse and aggregate the data
survival_rates = df.groupby(['AgeGroup', 'Sex'])['Survived'].mean().unstack()
print("\nSurvival Rates by Age Group and Sex:")
print(survival_rates)
family_size_survival = df.groupby('FamilySize')['Survived'].mean()
print("\nSurvival Rates by Family Size:")
print(family_size_survival)
# Step 6: Visualise insights
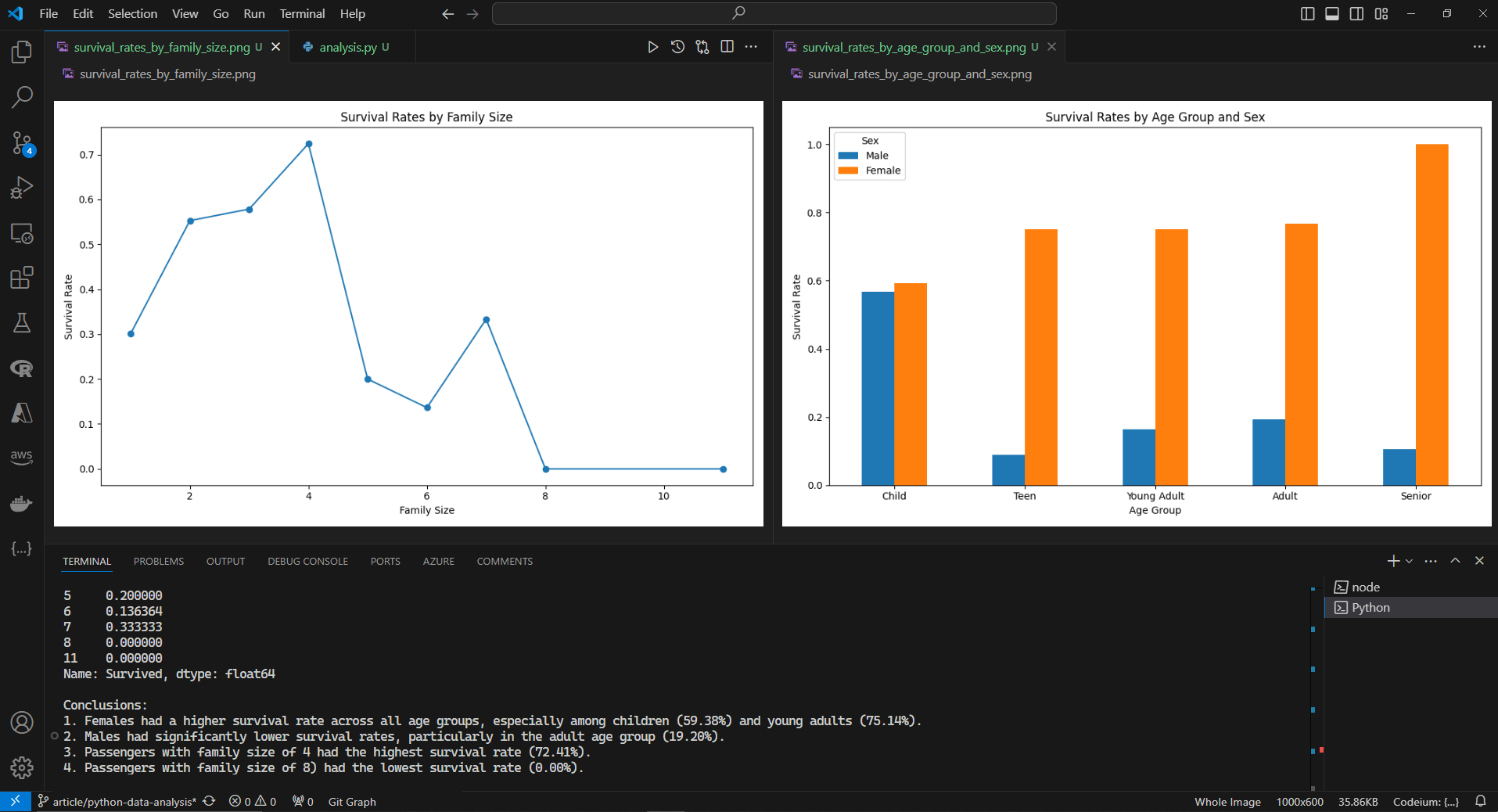
# Survival rates by AgeGroup and Sex
survival_rates_plot = survival_rates.plot(kind='bar', figsize=(10, 6), title='Survival Rates by Age Group and Sex')
plt.ylabel('Survival Rate')
plt.xlabel('Age Group')
plt.legend(title='Sex', labels=['Male', 'Female'])
plt.xticks(rotation=0)
plt.tight_layout()
plt.savefig('survival_rates_by_age_group_and_sex.png')
plt.close()
# Survival rates by Family Size
family_size_survival_plot = family_size_survival.plot(kind='line', figsize=(10, 6), marker='o', title='Survival Rates by Family Size')
plt.ylabel('Survival Rate')
plt.xlabel('Family Size')
plt.tight_layout()
plt.savefig('survival_rates_by_family_size.png')
plt.close()
# Step 7: Draw Conclusions
# Insights from survival rates by AgeGroup and Sex
highest_female_child_survival = survival_rates.loc['Child', 1] * 100
highest_female_young_adult_survival = survival_rates.loc['Young Adult', 1] * 100
lowest_male_adult_survival = survival_rates.loc['Adult', 0] * 100
print("\nConclusions:")
print(f"1. Females had a higher survival rate across all age groups, especially among children ({highest_female_child_survival:.2f}%) "
f"and young adults ({highest_female_young_adult_survival:.2f}%).")
print(f"2. Males had significantly lower survival rates, particularly in the adult age group ({lowest_male_adult_survival:.2f}%).")
# Insights from survival rates by Family Size
highest_survival_family_size = family_size_survival.idxmax()
highest_survival_rate = family_size_survival.max() * 100
lowest_survival_family_size = family_size_survival.idxmin()
lowest_survival_rate = family_size_survival.min() * 100
print(f"3. Passengers with family size of {highest_survival_family_size} had the highest survival rate ({highest_survival_rate:.2f}%).")
print(f"4. Passengers with family size of {lowest_survival_family_size}) had the lowest survival rate ({lowest_survival_rate:.2f}%).")
This code can be run on your laptop or PC in an IDE or Jupyer Notebook by creating a new file in your IDE like 'analysis.py' and pasting in the code. Then using 'python analysis.py' to run it. This saves the following plots and prints the conclusions to the console.
However in an organisation, you might actually run your code in the cloud or remote servers. This allows for more power, scripts run quicker, can connect to larger datasets and enables collaboration. Learning about cloud computing and the big providers like AWS, Azure and Azure Databricks and Google Cloud is worthwhile but not in scope for this article. There are links in the next section to learn more about these.
Resources, communities and projects for learning
Whether you're learning Python for data analysis, data science or tackling real-world projects, these further learning resources will guide you through key topics like analysis, visualisation, machine learning and cloud computing basics.
Resources
- Python for Data Analysis - great book to learn more on data analysis with Python
- Python Data Science Handbook
- Practical Statistics for Data Scientists - my most used reference book for statistical concepts
- Kaggle Learn
- freeCodeCamp Data Analysis with Python
- Cloud computing - AWS, Azure, Google Cloud
- Data Analyst Roadmap
- Data Scientist Roadmap
- Courses on YouTube
- Polars - an upcoming faster alternative to Pandas
Communities
Project ideas
- Analyse sales data to identify trends
Use the Superstore Sales Dataset to explore sales performance by region and category, and visualise monthly or yearly trends.
- Analyse global COVID-19 data
Use the COVID-19 Data Repository by Our World in Data to track global case trends, vaccination progress, and create visualizations to uncover regional patterns.
- Scrape e-commerce websites to compare product prices
Learn web scraping with tools like BeautifulSoup and Selenium to collect and analyse product prices from e-commerce websites.
- Segment customers using a clustering model
Use the Online Retail Dataset to group customers based on purchasing behavior and derive actionable insights for marketing.
- Perform a time-series analysis on stock market data
Fetch historical stock prices using the Yahoo Finance Dataset and analyse trends to forecast future prices with statistical models.
Conclusion
If you made it through all of this article, well done! We covered lots of ground. This guide will serve as a useful reference to return to on your learning journey. Keep going and keep learning! The number one takeaway is to get hands-on and do your own data analysis to solve a real problem in either your current role or in personal projects.
Analysis and statistics can solve all kinds of problems, but thinking through how you solved the problem or answered a question with data and statistics are the main things. These show your analytical mind working to solve problems and communicate insights clearly.
Learning Python for data analysis provides a strong foundation for working with data effectively. Start with the Python basics like data structures and libraries, practice real-world projects, and expand into advanced topics like machine learning and LLMs. With consistent practice, you'll soon be able to collect, analyse, and visualise data to derive valuable insights effectively with Python.
If you enjoyed this article be sure to check out other articles on the site 👍 you may be interested in: